




梯度下降算法、随机梯度下降算法(SGD)、小批量梯度下降算法(mini-batch SGD)、动量法(momentum)、Nesterov动量法有一个共同的特点是:对于每一个参数都用相同的学习率进行更新。
但是在实际应用中,各个参数的重要性肯定是不一样的,所以我们对于不同的参数要动态的采取不同的学习率,让目标函数更快的收敛。
AdaGrad算法就是将每一个参数的每一次迭代的梯度取平方累加后在开方,用全局学习率除以这个数,作为学习率的动态更新。
表示第i个参数的梯度,对于经典的SGD优化方法,参数
的更新为:
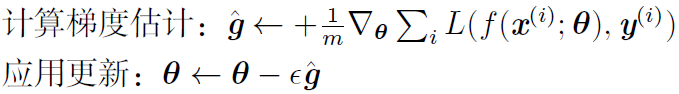
再来看AdaGrad算法表示为:
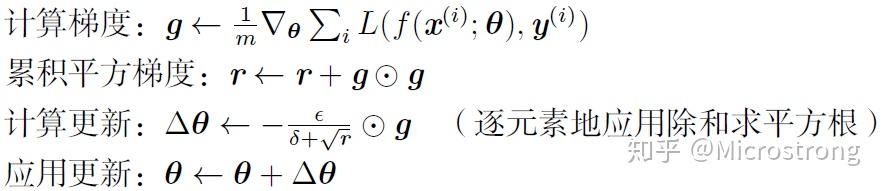
其中,r为梯度累积变量,r的初始值为0。为全局学习率,需要自己设置。
为小常数,为了数值稳定大约设置为
。
(1)从AdaGrad算法中可以看出,随着算法不断迭代,r会越来越大,整体的学习率会越来越小。所以,一般来说AdaGrad算法一开始是激励收敛,到了后面就慢慢变成惩罚收敛,速度越来越慢。
(2)在SGD中,随着梯度 的增大,我们的学习步长应该是增大的。但是在AdaGrad中,随着梯度g的增大,我们的r也在逐渐的增大,且在梯度更新时r在分母上,也就是整个学习率是减少的,这是为什么呢?
这是因为随着更新次数的增大,我们希望学习率越来越慢。因为我们认为在学习率的最初阶段,我们距离损失函数最优解还很远,随着更新次数的增加,越来越接近最优解,所以学习率也随之变慢。
(3)经验上已经发现,对于训练深度神经网络模型而言,从训练开始时积累梯度平方会导致有效学习率过早和过量的减小。AdaGrade在某些深度学习模型上效果不错,但不是全部。
【1】深度学习,Ian Goodfellow / Yoshua Bengio所著。
【3】adagrad原理
我的个人微信公众号:Microstrong
微信公众号ID:MicrostrongAI
公众号介绍:Microstrong(小强)同学主要研究机器学习、深度学习、图像处理、计算机视觉相关内容,分享在学习过程中的读书笔记!期待您的关注,欢迎一起学习交流进步!
个人博客:

