




一、大模型发展的前世今生
1、AI 大模型的进化简史:从神经网络到预训练大模型
自 1956 年,“人工智能”概念提出开始,已经有了近 70 年的发展历史,经历了三个发展阶段,即萌芽期(1950-2005),探索期(2006-2019),发展期(2020 年以后),不过真正大模型的历史还要从 2006 年 Deep Learning 首次在 Science 上发表开始,不过在 2012 年之前,大模型的探索与学习的关注度并不是很高。
2012 年,AlexNet 战胜 ImageNet 这一标志性事件,引发了行业对深度学习的关注和研究,而谷歌、百度等行业先行者也是在这一时期开始重视 AI 的发展。2013 年 Google Brain 项目发布了深度学习模型 DistBelief,为大规模分布式训练奠定基础。2014 年,被誉为 21 世纪最强大算法模型之一的 GAN(对抗式生成网络)诞生,标志着深度学习进入了生成模型研究的新阶段。2017 年, Google 又提出了 Transformer,这成为 GPT 发展的基础。
说起 Transformer,那就不得不提那篇传奇论文《Attention Is All You Need》,这篇论文不仅仅成为大模型研究的必读参考文献,该论文的 8 位作者也成为大模型创投圈炙手可热的人物,据悉,该论文的 8 位作者,仅有一位留在了谷歌,剩下的 7 位纷纷加入了创业大军,他们创立的 4 家公司中,有 3 家成为独角兽,其中包括 Adept、Character.AI、Cohere,而在这些独角兽背后站着的是谷歌、英伟达、Salesforce 等行业先行者。
不过让人意外的是,作为行业先行者,谷歌并没有率先发布令市场轰动的产品,反而是一家 2015 年 12 月成立的创业公司,引领了接下来大模型的发展,这家公司便是 OpenAI。
2018 年 OpenAI 发布 GPT-1 模型,标志着预训练模型在自然语言处理领域的兴起。2019 年,OpenAI 和 Google 又分别发布了 GPT-2 与 BERT 大模型,意味着预训练大模型成为自然语言处理领域的主流。
2020 年,大模型进入快速发展阶段,当年 OpenAI 推出了 GPT-3,模型参数规模达到了 1750 亿,成为当时最大的语言模型,并且在零样本学习任务上实现了巨大性能提升。随后,更多策略如基于人类反馈的强化学习(RHLF)、代码预训练、指令微调等开始出现,被用于进一步提高推理能力和任务泛化。
2022 年 11 月,OpenAI 推出了搭载 GPT3.5 的 ChatGPT,其逼真的自然语言交互与多场景内容生成能力,迅速火爆全网,2023 年上半年的 AI 热潮也就此展开。
2023 年,OpenAI 发布超大规模多模态预训练大模型 GPT-4,具备了多模态理解与多类型内容生成能力。谷歌推出 PaLM2 模型,Meta 发布 LLaMA-13B,微软基于 ChatGPT 打造 New Bing Windows 全面集成 Copilot。
国内,百度率先发布文心一言,随后阿里、商汤、360、华为等企业纷纷发布自己的大模型,复旦、清华、哈工大、中科院等学院派,也发布了各自的大模型,中小非上市公司印象笔记、医联科技、左手医生等也推出了行业大模型,市场进入了“百模混战”格局。
2、5 年后全球大模型市场规模破千亿美元,国内破千亿元人民币
大模型作为通用性技术,在自然语言处理、计算机视觉、语音识别、文本识别、推荐系统等多个领域均能展现其突出的作用,如何判断其市场规模在学术上仍有较多的争论,不同机构根据统计方法的不同,所得出的结论也有所出入。
其中,根据大模型之家的测算,预计到 2023 年,全球大模型市场规模将达到 210 亿美元,到 2028 年,其规模将达到 1095 亿美元。
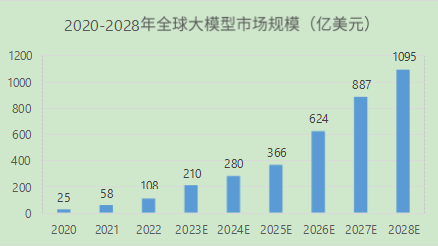
根据国际数据公司 IDC 预测,全球 AI 计算市场规模将从 2022 年的 195.0 亿美元增长到 2026 年的 346.6 亿美元。其中,生成式 AI 计算市场规模将从 2022 年的 8.2 亿美元增长到 2026 年的 109.9 亿美元。
而中国庞大的市场需求和丰富的人才储备,为大模型的发展壮大提供了有利的客观条件,大数据之家预测,中国大模型产业市场规模将达到 147 亿元人民币,并在 2028 年达到 1179 亿元。

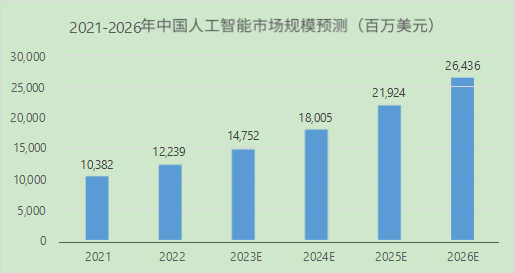
而 IDC 对基于大模型的 AI 市场规模进行了预测,预计中国人工智能市场规模在 2023 年将超过 147 亿美元,到 2026 年这一规模将超过 264 亿美元。
3、小结
通过对 AI 大模型发展史的梳理可以发现 AI 的基础研究发源并发展于美国,在基础大模型方面美国具有开创性作用,而国内大模型厂商更多扮演者追随者的角色,不过国内人工智能市场规模大,增长速度快,这又对人工智能的发展集聚数据燃料,提出新的落地需求,中国人工智能或在这样的环境下,率先在场景落地上赶超美国。
二、大模型进入“百模混战”时代
1、全球已发布大模型超 200 个,中美数量占全球的九成
虽然 ChatGPT 点燃了大模型发布的热情,不过早在 ChatGPT 发布之前,全球已经发布了不少大模型,《中国人工智能大模型地图研究报告》显示,2019 年 美国已经有了 4 个大模型,而中国 2020 年有了 2 个大模型,此后每年都有大模型发布,仅仅 2023 年的前五个月,中美分别有 19、18 个大模型发布。
截至 2023 年 5 月底,国内 10 亿级参数规模以上基础大模型至少已发布 79 个,而美国这一数字为 100 个,全球累计发布大模型 202 个,中美两国大模型的数量占全球大模型数量的近 90%,中国大模型数量已进入第一梯队。

发布大模型的机构可以分为四种类型,互联网公司、学术/研究机构、AI 公司及行业公司。
国内大模型呈快速发展之势,在以下几个方面表现突出:
一是,大模型应用越来越广泛,在自然语言处理、图像识别、语音识别、内容生成等多个领域有着广泛应用。
二是,大模型算法丰富,国内的模型上除了 GPT 之外,还对 BERT、ALBERT、NEZHA 等进行了广泛的探索。
三是,大模型性能不断提升,国内大模型玩家纷纷加大对 AI 的研发投入。据钛媒体·钛度图闻不完全统计 2022 年,华为在研发费用上投入 1615 亿元,成为研发投资资金最多的企业;其次,腾讯以 614 亿元排名第二,阿里以 555 亿元排名第三,他们在硬件和软件领域的大规模投入,大大提高了大模型的运算速度和效率。
四是,大模型研究成果不断涌现,国内以清华、复旦、哈工大等高校也推出了自己的大模型,国内机构在 NLP、CV 等领域也拿到了多个国际级别的冠军。
然而不得不承认的是,国内大模型迅猛发展的同时也面临着基础模型研发能力不足,部分行业数据搜集整理难度大等问题。
据国外风投数据公司 PitchBook 的数据,2023 上半年,全球人工智能领域共计发生融资 1387 件,筹集融资金额 255 亿美元,平均融资金额达 2605 万美元。
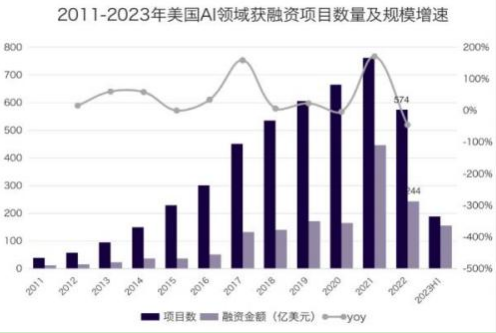
根据 Crunchbase 数据库 2011-2023 年共计 3658 个 AI 领域融资项目(仅统计 500 万以上融资金额的项目,且融资公司所在地为美国),美国 AI 领域融资项目数及融资金额稳步增长。2022 年美国风投 AI 领域融资项目数为 574 个,2011-2022 年 CAGR 达 29.3%;2022 年美国 AI 领域融资金额为 243.5 亿美元,2011-2022 年 CAGR 达 422.5%。
据业界不完全统计,2023 年上半年,美国 AIGC 一级市场中,硅谷在人工智能领域共完成了 42 起融资,总金额约 140 亿美元,占世界总融资金额的 55%。平均轮次融资金额为 3.3 亿美元,是平均融资水平的近 13 倍之多。其中,8 家人工智能明星独角兽公司拔地而起,平均轮次融资金额 3.3 亿美元。

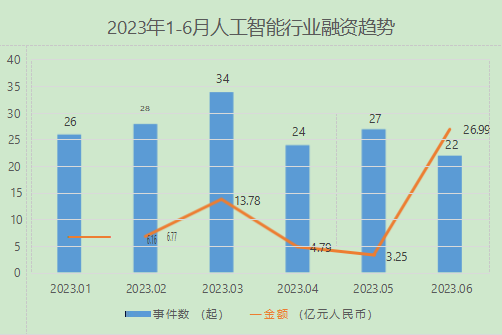
据国内商业信息服务平台企名片数据显示 2023 上半年,国内人工智能领域共发生 161 起投融资事件,其中包括人工智能核心技术 44 起,人工智能基础 支撑 43 起,人工智能应用场景 40 起,人工智能通用场景 34 起。较去年同期减少 153 起,同比下降 49%; 2023 上半年度国内人工智能领域投融资交易事件涉及总金额 61.74 亿元,较去年同期减少 99 亿元,同比下降 62%。
据钦媒体数据,2023 年上半年,国内披露获得投资的大模型公司只有大约 20 家,融资额普遍在千万到数亿元之间。其中,获得融资金额最多的是大模型初创公司 MiniMax,其在 6 月 1 日完成了超 2.5 亿美元的新一轮融资,目前该公司估值超 12 亿美元,被冠以“腾讯首次投资的创企”称号。此外,成立于 2021年的西湖心辰分别在 2023 年 3 月、 4 月接连完成了两笔融资,融资速度很快。

据钛媒体不完全统计,腾讯投资、创新工场、奇绩创坛、红杉中国是较活跃的投资机构,投资企业均达到 3 家,其次是 BV 百度风投和智谱 AI,投资企业分别为 2 家,大多数机构投资的企业仅为 1 家,而一向活跃的高瓴创投、深创投没有公开数据显示其进行过 AI 大模型赛道的投资 IDG 资本、经纬创投、真格基金等头部 VC 的出手也较少。
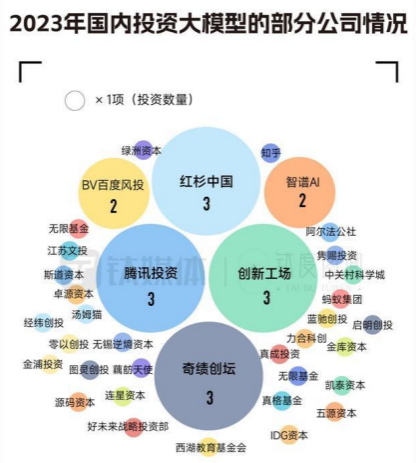
这主要是因为,大模型创业是极其烧钱的,据估算,大模型训练一次的成本介于 200 万美元-1200 万美元之间。即便是有马斯克和微软支持的 OpenAI 也要不断融资来维持,仅 2022 年,其就亏损了 5.4 亿美元左右。
所以,国内的通用大模型玩家主要还是百度、阿里、腾讯、华为等大型企业,而创业公司更多是寻找可落地的场景来实现变现。
3、“龙头大模型+”是当前大模型发展主要模式
虽然大模型发布数量不断增长,然而对于大模型如何落地变现,仍在不断探索中,据中国电信研究院分析,国外行业大模型发展模式主要有三种,且以前两种发展模式为主。
一是目前国际巨头多采用这种模式,如谷歌、微软、Meta 等龙头厂商利用大模型重构原有业务,比如微软利用 GPT-4 全面“龙头大模型+原有业务”赋能 A zure 云、Office365、Dynamics365 等传统业务。这种模式的优势在于可以利用大模型的强大语言能力,提升原有业务的智能化水平,同时也可以借助原有智车业务的数据和用户资源,增强大模型的应用相关性和准确性。
二是“龙头大模型+外部行业数据”。这种模式是国内创业公司普遍采用的方式,通过直接调用 API 或基于 GPT 大模型微调改进自身 AI 产品,比如哈维基于 GPT 及行业数据推出“AI 法律助手”。这种模式的优势在于可以利用龙头大模型的先进技术和算力,快速打造出具有行业特色和竞争力的 AI 产品,同时也可以借助外部数据源,增强行业相关性和准确性。
三是“开源大模型+ 自有行业数据搭建行业大模型”。这种模式多适用于有着丰富的行业数据积累的中大型企业。例如基于开源模型研发,实现 LLM 与金融垂直领域知识的深度融合。这种模式的优势在于可以充分利用自有数据的质量和数量级,打造出更专业、更精准的行业大模型,同时也可以借鉴开源大模型的技术和经验,提升训练效率和效果。
总体而言,基础大模型训练成本高,研发难度大,这决定了大模型会遵照“赢者通吃”的规律,未来市场上仅存几个龙头大模型,而围绕龙头大模型的创业生态将逐步形成。
在商业模式上,根据天风证券研报,目前大模型主要的盈利模式包括交易量收费、 定制开发费用、服务费用和订阅收费。
交易量收费主要是根据客户每月使用的 API 调用或交易量收取费用。定价标准通常是按交易量计算,例如每千个 API 调用收取一定的费用。
定制开发费用是,如果客户需要特定领域的 AI 模型,公司通常会收取定制开发费用。定价标准通常取决于开发的难度和时间成本。
服务费用指,根据提供数据处理、标注和质量控制服务等来收取费用。
订阅费用是指,客户可以根据需要选择不同的订阅级别,如基本、标准或高级。订阅费用通常按月或按年收取,并根据所需服务的数量和类型进行定价。
4、国内外代表性大模型介绍
1)OpenAI:大模型热度引爆者 GPT 系列模型引领者
2015 年 12 月 OpenAI 由马斯克、美国创业孵化器 Y Combinator 总裁阿尔特曼、全球在线支付平台 PayPal 联合创始人彼得·蒂尔等硅谷科技大亨创立。2023 年 4 月,OpenAI 完成 3 亿美元最新一轮融资,累计完成 103 亿美元融资,最新估值达 270 亿 -290 亿美元。
OpenAI 是基于 Transformer 基础模型推出了 GPT 系列大模型。GPT(Generative Pre-trained Transformer) 即生成式预训练 Transformer 模型,模型被设计为对输入的单词进行理解和响应并生成新单词,能够生产连贯的文本段落。
2019 年、2020 年,OpenAI 分别发布了 GPT-2 和 GPT-3,但并未在市场上引起轰动。2022 年 11 月,OpenAI 发布 ChatGPT。ChatGPT 基于 GPT 技术,通过大量的语料训练,可以模拟人类的对话方式和思维方式,从而实现了与人类的交互。相比传统的聊天机器人,ChatGPT 在语言理解和回答问题方面更加准确和自然,更加符合人类的交流习惯。ChatGPT 的操作非常简单,用户只需输入自己想要说的话 ChatGPT 就会立刻回答,回答内容也十分丰富,包括天气、新闻、娱乐等,随着用户的探索,ChatGPT 在办公、写论文等多个领域有着良好的体验,这些优点让 ChatGPT 迅速引爆市场,开启了 2023 年的人工智能热潮。
2023 年 3 月,OpenAI 又推出了 GPT-4,这是其在深度学习扩展方面最新里程碑,GPT-4 是一个大型多模态模型(接受图像和文本输入、输出),虽然在许多现实场景中的能力不如人类,但在各种专业和学术基准测试中表现出人类水平的性能。例如,它在模拟律师资格考试中的成绩位于前 10%的考生,而 GPT-3.5的成绩在后 10%。GPT-4 不仅在文学、医学、法律、数学、物理科学和程序设计等不同领域表现出高度熟练程度,而且它还能够将多个领域的技能和概念统一起来,并能理解其复杂概念。
除了生成能力,GPT-4 还具有解释性、组合性和空间性能力。在视觉范畴内,虽然 GPT-4 只接受文本训练,但 GPT-4 不仅从训练数据中的类似示例中复制代码,而且能够处理真正的视觉任务,充分证明了该模型操作图像的强大能力。另外, GPT-4 在草图生成方面,能够结合运用 Stable Difusion 的能力,同时 GPT-4 针对音乐以及编程的学习创造能力也得到了验证。
2)谷歌:大模型基础理论贡献者
谷歌对人工智能的贡献,尤其是对基础理论的贡献是不言而喻的,即便在聊天机器人上被 OpenAI 捷足先登,但谁也不敢小觑谷歌的实力,其推出了 BERT 模型、LaMDA 模型、Switch Transformer 模型、通用稀疏语言模型 GLaM、PaLM-E 多模态视觉语言模型(VLM)等多个基础模型来多方面提高大模型性能。
谷歌最早在 2017 年提出 Transformer 网络结构,成为过去数年该领域大多数行业进展的基础。随后在 2018 年,谷歌提出的 BERT 模型,在 11 个 NLP 领域的任务上都刷新了以往的纪录。和 GPT 相比,BERT 最大的区别就是使用文本的上下文来训练模型,而 GPT 专注于文本生成,使用的是上文。BERT 使用了 Transformer 的 Encoder 和 Masked LM 预训练方法,因此可以进行双向预测。而 OpenAI GPT 使用了 Transformer 的 Decoder 结构,利用 Decoder 中的 Mask 只能顺序预测。BERT 无需调整结构就可以在不同的任务上进行微调,在当时是 NLP 领域最具有突破性的一项技术。
2023 年 2 月 6 日,谷歌推出聊天机器人 Bard Bard 背后是 LaMDA 在提供后端支撑。LaMDA 是继 BERT 之后,谷歌于 2021 年推出的一款自然对话应用的语言模型,可以实现拟物化与用户交谈。
此外,谷歌还推出了 Switch Transformer 模型,该模型进一步提升大模型参数,可实现简单且高效计算;推出的通用稀疏语言模型 GLaM 训练成本抵御 GPT-3,相同数量下的表现也有提升;2023 年 3 月,谷歌和柏林工业大学 AI 研究团队推出了迄今最大视觉语言模型--PaLM-E 多模态视觉语言模型(VLM)。该模型较 ChatGPT 新增了视觉功能。
3)百度文心一言:国内首个大模型发布者,AI 应用场景覆盖广
2023 年 3 月 16 日,百度官方发布“文心一言”。“文心一言”是百度研发的知识增强大语言模型,拥有文学创作、商业文案创作、数理逻辑推理、中文理解和多模态生成五大能力。文心一言在百度 ERNIE 及 PLATO 系列模型基础上研发而成,关键技术包括监督精调、人类反馈的强化学习、提示、知识增强、检索增强以及对话增强。其中,百度在知识增强、检索增强和对话增强方面实现技术创新,使得文心一言在性能上实现重大进步。
在商业模式上,文心一言或将提供大模型 API 相关功能。技术上来说,文心大模型已经具备了搜索、文图生成等功能,并成功得到应用,这些能力或将集成于文心一言。此外,据百度官方信息,文心一言或将提供大模型 API 相关功能。目前,文心大模型提供的大模型 API 包括 ERNIE-ViLG 文生图和 PLATO,以及正在开发的 ERNIE 3.0 文本理解与创作。ERNIE 3.0 文本理解与创作与文心一言官网相关联,能够认为,文心一言等生成式对话产品或将同样提供大模型 API 相关功能。
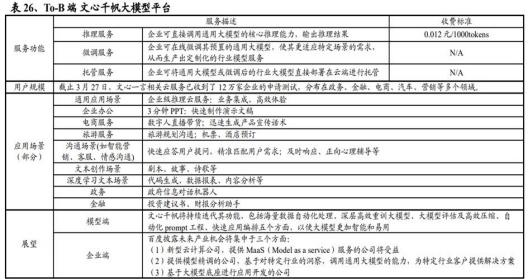
文心千帆提供开发运维管理一体化服务平台。3 月 27 日,百度于首批测试企业闭门沟通会中正式推出企业级“文心千帆”大模型平台,其中包括文心一言在内的大模型服务,还提供相应的开发工具链及整套环境,未来文心千帆还会支持第三方的开源大模型,并探索具体应用场景。
4)MiniMax:国内大模型创业企业,新晋独角兽
MiniMax 成立于 2021 年 12 月,具备自研文本、语音等多模态融合的通用大模型能力,目前自研了文本到视觉(text-to-visual)、文本到语音(text-to-audio)、文本到文本(text-to-text)三个模态的基础模型架构,并在基础模型之上构建起一个计算推理平台。
MiniMax 联合创始人为前商汤科技副总裁、通用智能技术负责人闫俊杰,也曾担任商汤研究院副院长。公司法定代表人、技术合伙人杨斌,则曾于 2014 年在中科院自动化所读硕士,在加拿大读完博士后,先后在 Uber AI 研究院,以及自动驾驶卡车领域有多年研发经验。
MiniMax 是国内通用大模型创业企业,2023 年 6 月拿到了腾讯等机构投资的 2.5 亿美元新一轮融资,成为国内大模型创业企业中单笔融资最高的企业,估值超 10 亿美元,成为国内大模型领域少有的独角兽。此前,MiniMax 已完成两轮融资,投资方包括米哈游、IDG 资本、高瓴创投、云启资本以及明势资本等。
To C 端,2022 年 11 月,MiniMax 发布虚拟聊天软件产品 -Glow,在 Glow 里,用户可以根据喜好创建有背景设定、有特定性格的智能体。通过内容生成与用户反馈,不断迭代背后大模型的 AI 能力,有一些类似 ChatGPT 背后的 RLHF。
2023 年 3 月 MiniMax 又上线了其自主开发的生成式对话 AI,背后大模型基于 Transformer,名为 Inspo,该 AI 定位于人工智能助手,具备写作、获取信息、提供建议等多项功能。
To B 端,2023 年 3 月,MiniMax 推出了面向企业用户的 API 开放平台,支持文本和语音模型的服务调用。
5)智谱 AI:千亿级超大规模预训练模型
智谱 AI 成立于 2019 年,由清华大学计算机系知识工程实验室的技术成果转化而来。随着 20 年 GPT-3 的问世及火遍全球,智谱 AI 也开始全力研究大模型并研发预训练架构。

2021 年 9 月,公司发布了一个百亿大模型。在 2022 年 8 月,智谱 AI 发布了千亿级超大规模预训练模型 GLM-130B,并主导构建高精度通用知识图谱,把两者有机融合为数据与知识双轮驱动的认知引擎。2023 年 3 月,公司研发了对话模型 ChatGLM,开始全面对标 ChatGPT。紧接着发布单卡开源版本 ChatGLM- 6B、多模态对话模型 VisualGLM-6B 并开源,升级对话模型 ChatGLM2。5 月 16日,360 集团和智谱 AI 宣布达成战略合作,双方共同研发千亿级大模型“360GLM”。

基于大模型基础智谱 AI 布局 AIGC,智谱 AI 推出了认知大模型平台 Bigmodel.ai,形成 AIGC 产品矩阵,包括高效率代码模型 CodeGeeX、高精度文图生成模型 CogView 等,提供智能 API 服务。也通过认知大模型链接物理世界的亿级用户、赋能元宇宙数字人、成为具身机器人的基座。
今年智谱 AI 已完成 B-2 轮融资,金额为数亿人民币,由美团战投独家投资,该轮投后估值为近 5 亿美金。
6)第四范式:国产 AI 独角兽
第四范式成立于 2014 年,是一家人工智能技术与服务提供商,业务是利用机器学习技术和经验,通过对数据进行精准预测与挖掘揭示出数据背后的规律,帮助企业提升效率、降低风险,获得商业价值。2020 年 4 月 2 日,第四范式完成 C+轮融资,C 轮总计融资金额达 2.3 亿美元,投后估值约 20 亿美元,并在 2022 年向港交所提供上市申请,于今年 7 月 3 日获得中国证监会的批准。
目前,第四范式已经完成超过 2000 个 AI 落地案例,服务领域包括金融、医疗、政府、能源、零售、媒体等。例如金融方面,第四范式与各大银行合作,深入底层系统共建 AI 应用体系,升级为以高维机器学习模型为主的实时智能决策系统,从信息化向智慧化发展。目前,第四范式服务的金融机构资产总规模超过 50 万亿。在医疗方面,第四范式与三甲大型综合性教学医院上海瑞金医院合作的 “瑞宁知糖”系列项目聚焦于虚拟代谢人研究和慢性病管理,目前已经在 30 多个省市的 400 多家医院投入使用。
今年 4 月 26 日,第四范式展示其大模型产品“式说 3.0”,并首次提出 AIGS 战略(AI-Generated Software):以生成式 AI 重构企业软件。此大模型经历了 3 个阶段,第一个阶段是式说 1.0,解决 GPT 技术应用时内容可信、数据安全和成本的三大问题,主要应用于文库问答。第二阶段为式说 2.0,在上一阶段的基础上加入文本、语音、图像、表格、视频等多模态输入及输出能力,增加了企业级 Copilot 能力。以与企业内部应用库、企业私有数据等进行联网,对信息和数 据进行分析。第三阶段在生成式和语言能力的基础之上,发力 Copilot 和思维链 COT(多步推理、复杂任务拆分、形成数据飞轮),改造传统 B 端企业软件的体验与开发效率。
第四范式今年合作多家基于其大模型产品。3 月 23 日,龙芯中科与第四范式进行战略合作,基于 LoongArch(龙架构)的 4Paradigm Sage AIOS 一体机已完成与龙芯 3C5000 系列芯片的深度适配工作,在龙芯 CPU 上实现 AI 训练及推理能力。5 月,我爱我家与第四范式合作,打造行业首个房产经纪大模型,提高知识、系统、人三者的融合度,提升智能决策水平,助推房产领域智能决策 AI+大模型生成式 AI 双轮驱动。
利润方面第四范式连续三年出现净亏损。根据招股书,2020 年至 2022年,第四范式收入分别为 9.42 亿元、20.18 亿元、30.83 亿元,同比增速为 105.0%、114.2%、52.7%。在净利润方面,第四范式亏损净额分别为 7.50 亿元、18.02 亿元及 16.53 亿元。

5、小结
从数量来看,截至目前,国内大模型发布数量与美国差距不大,但从整体的影响力来看,国内大模型还没像 OpenAI、谷歌一样形成世界性的影响力,此外,由于大模型对人才、资本和技术的制约,国内一级市场对大模型项目的投资并不如美国那样火热,国内更倾向于利用龙头企业的开源模型来做应用落地的创业。
关于国内大模型与美国的大模型的差距,业内人士看法不一,李彦宏曾表示,文心一言和 OpenAI 差距大概是一两个月,科大讯飞创始人、董事长刘庆峰也曾表示,中国 AI 领域的算法没有问题,但算力似乎始终被英伟达按住,他承认目前与 ChatGPT 还有一定的差距,但也表示 2023 年 10 月份,科大讯飞将发布通用大模型,全面对标 ChatGPT ,且要实现中文全面超越,英文跟它相当。到 2024 年上半年对标 GPT-4。而搜狗创始人王小川则认为,OpenAI 领先国内三年时间,但 2023 年 6 月,他去硅谷做了一番考察后,他认为国内应用层做的更出色,起码快美国三步。
美国浓厚的工程师文化,使得美国在基础研究上保持领先地位,但也可以发现,许多工程师对于大模型的应用并没有什么经验,此外落地应用涉及的交付、维护等环节需要人力支持,美国在这方面并无优势,反而是国内企业创业的初衷就为落地而去,可能会在落地应用上领先一步。
三、中美 AI 大模型在千行百业的赋能表现
大模型能否落地一方面取决于大模型的性能,另一方面与所落地行业的特点是分不开的。数据是大模型的基础燃料,这就意味着数据量大、数据质量高、数据多样性强的行业能够为大模型提供充足的训练和微调的数据,而技术需求高、创新能力强、竞争激烈的行业自身就有着拥抱新技术的热情,这些因素决定下,大模型在各国、各行业的成熟度并不一致,在各个应用落地的表现也有所不同。
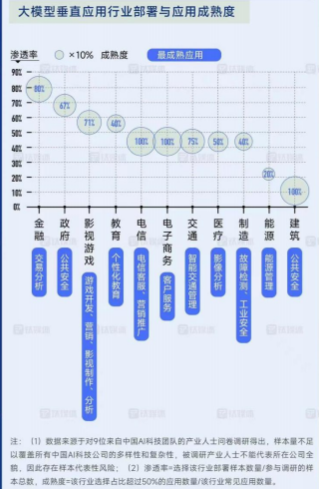
目前,国内外大模型已在办公、教育、医疗、金融、文娱、交通等领域落地应用,从行业渗透率来看,金融业的渗透率最高,已达 78%,在微软、金山办公等龙头企业的带动推广下,在办公领域的渗透率也比较可观,而能源和建筑行业的渗透率较低。
1、AI+办公:美国巨头引领潮流,国内厂商奋起直追
如果说, 自动化是解放蓝领,那么 AI 大模型便是来解放白领的,在微软、Adobe 等美国办公软件巨头的引领下,大模型在办公领域的渗透迅速展开。国内金山办公、福昕软件等办公软件龙头企业也一直在探索 AI 与办公产品的结合。
用户可以通过大模型进行文档摘要和自动化翻译,提高文档处理的效率;通过语音识别和自然语言处理技术实现语音助手,帮助用户处理日常任务和安排会议;通过自动化的数据处理和分析,提供决策支持等,促进团队间的沟通和合作。大模型在信息管理和知识管理方面也发挥重要作用能够实现智能搜索、文档自动分类和知识图谱构建,帮助员工更轻松地获取和利用内部和外部的知识资源。大模型还可以应用于智慧办公的单据管理和报销流程。通过图像识别和文本分析,大模型可以自动识别和分类各种单据,如发票、收据、报销申请等。
目前在 AI 大模型+办公领域,更多还是成熟企业通过接入外部龙头大模型,来给原有产品增加更多 AI 功能,在该领域的创业项目并不多。
1)微软:智能办公引领者
2023 年 3 月 16 日,微软正式发布 Microsoft 365 Copilot,并集在微软 365 的多个应用程序中,包括 Word、 Excel、PowerPoint、Outlook、Teams 等。它集成了 GPT-4 的功能,以聊天机器人的模式出现在产品的右侧。用户通过向其发号指令,便可自动生成文字、表格、演示文稿等内容。
Microsoft 365 Copilot 可以根据用户的简短提示,在 Word 中生成文档的初稿。在 Excel 中帮助用户分析数据,生成图表和报告,并提供有用的见解和建议。在 PowerPoint 中创建漂亮的幻灯片,并根据用户在微软图形中的数据添加相关内容。在 Teams 中帮助用户协作沟通,分享信息,创建任务和计划,并提供相关的反馈和建议。遵循微软对数据安全和隐私的承诺,在企业环境中保护用户的数据不被滥用或泄露。在 Outlook 中帮助用户管理日程安排,回复邮件,编写摘要和提纲,并提供适当的语气和礼貌。
Microsoft 365 Copilot 的推出为微软提供了新的收入增长点,根据国泰君安研报预测,2022 年 Microsoft365 机构订阅的 ARPU 约为 103 美元,此次 Copilot 服务的试点价格有望推动 ARPU实现接近翻倍增长。
2)金山办公:国内办公龙头,已接入多个大模型
金山办公是国内办公软件龙头,也是最早探索 AI 技术落地办公应用的先行者。2017 年,AI 在金山办公内部首次被提升到战略层面,2018 年正式提出多屏、内容、云、AI 的发展战略。
金山办公已经将公司的产品逐步添加 AI 功能,比如智能美化、智能校对、智能辅助写作、全文翻译、图像识别等。此外,金山办公还接入了多个大模型供应商,来满足用户 AI 创作需求,目前已接入 MiniMax、百度文心、 CopyDone 等大模型。
2023 年 4 月 18 日,金山办公发布了 WPSAI 的 Demo 演示视频,官宣 WPSAI 将嵌入金山办公全线产品。率先进入内测阶段的是具备 AI 能力的 WPS 轻文档,这是一款对标 NotionAI 等轻办公产品的在线内容协作编辑工具,可以借助大模型自动生成新闻稿、工作周报、运营策划案等;也可以实现多轮对话,持续就某个主题进行讨论;也可以对现有文档进行改写、扩写、缩短、润色等;还可以对指定文档生成主旨摘要、文章大纲等功能。
2、AI+金融:美国发展较成熟,国内也已进入应用阶段
AI+金融指人工智能与金融的全面融合,以人工智能、大数据、云计算、区块链等高新科技为核心要素,全面赋能金融机构,提升金融机构的服务效率,拓展金融服务的广度和深度,使得全社会都能获得平等、高效、专业的金融服务,实现金融服务的智能化、个性化、定制化。AI 应用场景涵盖前中后台中的市场营销、产品设计、风险管控、客户服务、运营支持等。据艾瑞咨询统计测算,2021 年 AI+金融核心市场规模达到 296 亿元,带动相关产业规模 677 亿元,到 2026 年,核心市场规模达到 666 亿元,CAGR 为 17.6%,带动相关产业规模 1562 亿元,CAGR 为 18.2%。数据显示,美国金融 AI 占比整体 AI 领域融资的 6.7%。
在 AI 大模型在金融领域的应用中,美国开发应用时间较早,并且掌握核心技术。目前已覆盖金融各领域,尤其在金融服务方面取得不小建树,应用趋近成熟。根据咨询公司 Evident 的最新数据,目前美国银行的招聘中,约 40%的空缺职位是与人工智能相关的职位,例如数据工程师和量化分析师,以及合规、道德治理等职位。摩根大通从 2023 年 2 月到 4 月在全球招聘 3651 个与人工智能相关的职位。美国在金融领域已成熟应用 AI 大模型处理金融业务,提供金融服务。
国内 AI+金融目前也已进入应用阶段,例如中国农业银行推出的大语言模型 服务 ChatABC,与美国对比,我国该领域开发投资积极性占比较高,叠加近期数据政策支持,有望追平美国 AI 大模型在金融领域的应用发展水平。
1)彭博 BloombergGPT:开启大模型在金融行业的开发和应用的第一步
2023 年 3 月,彭博社发布了专门为金融领域打造的大型语言模型(LLM)——BloombergGPT。
金融领域的复杂性和独特的术语需要特定领域的模型,BloombergGPT 代表了这项新技术在金融行业的开发和应用的第一步。该模型将协助彭博改进现有的金融 NLP 任务,例如情感分析、命名实体识别、新闻分类和问答等。此外,BloombergGPT 将释放新的机会,整合彭博终端上的大量可用数据,以更好地帮助该公司的客户,同时将人工智能的全部潜力带入金融领域。
彭博支持大量且多样化的 NLP 任务,这些任务将受益于新的金融感知语言模型。彭博研究人员还开创了一种混合方法,将财务数据与通用数据集相结合,训练一个模型,在财务基准上取得不错的结果,同时在通用 LLM 基准上保持竞争性。
BloombergGPT 在两大类 NLP 任务中的表现:金融专业任务和一般任务。
彭博的机器学习产品和研究团队与公司的人工智能工程团队合作,利用公司现有的数据创建、收集和管理资源,构建了迄今为止最大的特定领域数据集之一。作为一家金融数据公司,彭博的数据分析师在四十年的时间里收集并维护了金融语言文档。该团队从庞大的金融数据档案中提取数据,创建了一个由英文金融文国咏合车档组成的包含 3630 亿个代币的综合数据集。
2)Lemonade:大模型在保险领域的试水者
Lemonade 是一家保险公司,他们应用大模型打造了 Maya 与 Jim。机器学习驱动的 Maya 个虚拟助手,可以收集信息、提供报价并处理付款。Maya 是一个功能强大的机器人,可确保客户在 3 分钟内收到付款并在 90 秒内获得保险。Maya 利用灾难早期检测系统可以对正在发生的灾难做出实时反应。该机器人会自动封锁区域,并向 Lemonade 的人工索赔团队发出潜在紧急情况的警报。Maya 还会帮助该公司在附近发生火灾和恶劣天气事件时通知用户。使用 AIMaya 不仅可以获得疑难问题的定制即时答案,还可以帮助他们更改现有政策。Maya 聊天 越多它就越聪明,因为机器学习模型几乎每天都会重新训练。Maya 由 NLP(自然语言处理)和 NAS(自然动作合成)推动。
Jim 也是机器学习驱动的机器人。据悉,它能够在没有任何人为参与的情况下管理整个索赔流程。2019 年,Jim 处理了约 20000 项索赔,并在无人参与的情况下支付了约 250 万美元。为 AIJim 提供支持的机器学习算法可以读取索赔的性质、严重程度以及客户是否处于紧急状态。除此之外,AIJim 还调查了虚假索赔的可能性。它通过将多年的行为经济学研究结合到对话中的每一个微小细节中,促使人们变得更加诚实,可以平均跟踪 370 万个信号。
3)中国农业银行 ChatABC:中国银行业大模型应用探索者
ChatABC 是中国农业银行推出的大语言模型服务。中国农业银行大语言模型是基于农行数据中台算法、算力、数据基础,结合开源通用大模型技术自主研发的人工智能对话机器人服务。
ChatABC 重点着眼于大模型在金融领域的知识理解能力、内容生成能力以及安全问答能力,对于大模型精调、提示工程、知识增强、检索增强、人类反馈的强化学习(RLHF)等大模型相关新技术进行了探索和综合应用,结合农业银行研发支持知识库、内部问答数据以及人工标注数据等金融知识进行融合训练调优,实现了金融知识理解和问答应用。
1.0 版本 ChatABC 大模型拥有百亿级参数,可初步具备自由闲聊、行内知识问答、内容摘要等多类型任务的服务能力,已在行内多个渠道以多轮问答助手、工单自动化回复助手等形式面向内部员工开放试用,并可通过 MaaS(ModelasaService)方式面向其他场景提供一站式决策辅助服务,未来将逐步形成大模型服务生态。
3、AI+医疗:数据制约下,国内渗透缓慢,美国数据优势明显,青睐研发环节
AI 大模型在医疗领域的应用场景可分为诊前、诊中、诊后,涉及诊前的药物研发、基因研究、预约就诊、预检分诊以及导诊,诊中的临床诊断、临床治疗、病历录入及药物检索,诊后的医保支付、报告获取、患者随访、康复管理及远程医疗等。
根据 Frost&Saliv数据显示 2020-2025 年 I+医疗市场规模呈现高增长状态,市场总规模在 2025 年将达 348 亿元,增速维持在 40%左右。根据观研数据中心数据显示 AI 人工智能细分市场中,影像、数据交换与存储、综合辅助诊断占比较高,占比分别为 34%、22%、13%。据动脉橙数据显示,从 2022 年 1 月 1 日至 2023 年 6 月 28 日全球生成式 AI 医疗领域累计投融资事件超过 160 起,累计投资金额超 57.1 亿美元。
可以说, AI+医疗市场前景广阔,一级市场活跃。
美国较早推行了医疗信息化,医疗行业有着丰富的结构化的数据,这也方便了美国企业在研发端发力,其中微软、谷歌、英伟达等科技巨头在 AI 医疗领域 布局积极,比如谷歌早在 2014 年就收购了 DeepMind 2016 年 DeepMind 就提出将算法应用到医疗保健领域,目前谷歌和 DeepMind 团队发布的医疗大模型 Med-PaLM 在医学考试中已经基本接近“专家”医生水平,2022 年 7 月 DeepMind 进一步破解了几乎所有已知的蛋白质结构,其 AlphaFold 算法构建的数据库中包含了超过 2 亿种已知蛋白质结构,为开发新药物或新技术来应对饥荒或污染等全球性挑战铺平了道路。
从国内来看,目前影响大模型在医疗领域渗透的主要问题在于数据,一方面医疗行业数据量非常大、质量较差,将医疗行业的数据进行整理清洗需要一个过程;另一方面医疗行业数据涉及患者隐私和国家安全等敏感信息,数据开放度低。尽管面临着数据困难,但国内科技企业一直在迎难而上,比如华为盘古大模型已经助力药品开发,百度文心一言发布了落地医药行业的产品 GBI-Bot,京东健康发布了“京医千询”医疗大模型等等。
从一二级市场来看,对于大模型+医疗,二级市场更多关注的是原有医疗信息化企业产品的智能化,而一级市场更多关注大模型在医药研发、辅助诊断等方面的应用。
1)医联:国内首款医疗大模型 medGPT 发布者
2014 年,医云科技,即医联,成立于四川成都,先后得到了红杉中国、腾讯、云锋基金、招银国际、华兴资本等国内知名机构的投资,最新一轮融资是 2021 年 12 月,由中国生物制药投资的 5.14 亿美元的 E 轮融资,估值近 40 亿美元。
医云科技是一家医疗解决方案提供商,旗下拥有医联通、医联 ME 和医联 APP 等产品,业务覆盖疾病筛查、医生教育、诊疗服务、药品配送、金融保险等服务。
2023 年 4 月 28 日,医联宣布成功研制国内首款大模型驱动的 AI 医生 medGPT,medGPT 是基于 Transformer 架构,目前参数规模为 1000 亿,可支持医疗场景下的多模态输入和输出。其中,预训练阶段使用了超过 20 亿的医学 文本数据,微调训练阶段使用了 800 万条的高质量结构化临床诊疗数据,并投入超过 100 名医生参与人工反馈监督微调训练。
medGPT 突破了 AI 医生无法与真实患者连续自由对话的难点,并在医疗问诊场景中支持多模态的输入和输出,在疾病的预防、诊断、治疗、康复四个重要环节实现智能化。
为验证 medGPT 的诊断准确率,医联抽取了 532 名复诊患者档案进行信息脱敏,并进行了模拟首诊实验。结果显示,医联 medGPT 的诊断结果与患者原有线下门诊的诊断吻合率超过 97.5%,证明了 AI 医生在医疗领域的价值和潜力。
2)云知声:基于山海大模型的门诊病历生成系统
云知声,成立于 2012 年,是一家专注于物联网人工智能,拥有自主知识产权的智能语音人工智能企业。云知声业务主要覆盖智慧生活和智慧服务两大场景,在包括家居、 车载、医疗、教育、政府、机器人等领域拥有广泛布局。
2023 年 5 月 26 日,云知声发布“云知声山海大模型”,并基于该模型发布了手术病历撰写助手、门诊病历生成系统、商保智能理赔系统三大医疗产品应用。
其中,门诊病历生成系统实现了诊室复杂环境下的降噪、医患角色区分、信息摘要及病历自动生成等功能。预计可提升医生的电子病历录入效率超过 400%,节约单个患者问诊时间超过 40%,提升医生门诊效率超过 66%。
4、AI+文娱:美国发展遇阻力,我国有望弯道超车
最近基于大模型的 AIGC 技术在影视、游戏、音频、动漫等多个领域落地应用,给数字文娱产业带来了可预见的巨大价值。AI 不仅能够帮助企业提高内容生产的效率,也能生成更加丰富多元、动态且可交互的内容,进而优化传统互动模式。AI 正从激发生产力、打造新内容、构建新体验多层面重塑着数字文娱行业。
大部分技术的起源在于美国,而美国理所当然地在 AI+文娱领域发展最早,并衍生多个大模型应用。不过近期美国 AI+文娱产业发展似乎受到较大的阻力。这主要体现在影视动漫领域以及音乐产业。2023 年迪士尼旗下漫威发布新片《秘密入侵》,因其片头为 AI 工具生成,而受到网上舆论猛烈抨击,并且此前的 AI 音乐同样受到大量抨击。
我国 AI+文娱发展有着多元化的特征,各个产业领域基本被覆盖,尤其头部公司,如华为、阿里等更是拥有着较为成熟的大模型。不过核心技术的开发创新仍值得我们重视,目前大部分模型技术及底层逻辑仍是借鉴美国,在部分领域我们仍与美国存在较大差距,例如游戏与语言生成技术。依托庞大的市场需求,在市场发展方面,未来我国有望弯道超车。
1)携程:首个旅游行业垂直大模型“携程问道”
近期携程发布了首个旅游行业垂直大模型“携程问道”,该模型自 2022 年开始研发。
携程在旅游业多年,积累了大量行业数据,为其行业大模型提供了充足的数据依靠。据报道,“携程问道”作为垂直大模型,实现了筛选 200 亿高质量非结构性旅游数据,结合携程现有精确的结构性实时数据以及携程历史训练的机器人和搜索算法,进行了自研垂直模型的训练。
AI 大模型的应用,可以为在线旅游平台创造更多的价值,助力企业实现降本增效,比如提高客服效率,为消费者进行线路规划,为消费者所遇到的景点、酒店等等各种疑问提供解答,从而节省消费者的决策时间。
“携程问道”可以为有明确规划的用户提供查询和引导预订的服务,为无明确规划的用户提供出行推荐服务,从而减少所需要的决策时间,为用户带去更加方便、快捷的旅游体验。
2)华为云盘古大模型:在数字文娱产业全面发展
华为云在影视动漫、数字内容、游戏等领域有着广泛应用。
在影视动漫领域,华为云将渲染任务搬到云上,通过乌兰察布云数据中心的百万核算力资源实现了“万核渲一图”。华为云的 MetaEngine 云原生智能渲染引擎,将人工智能与计算机图形技术相结合,实现了 AI 渲染加速,让内容制作走上快车道。
在数字内容领域,华为云通过对 PB 级的音视频数据进行训练,让数字人的生产效率得到极大提升,让每个人实现“数字人自由”。
在游戏领域,华为云可以帮助游戏美术设计师确定游戏风格,辅助世界观框架、剧情及玩法的创意设计,优化玩家的和 NPC 交互方式和体验。
华为云盘古大模型 3.0 包括三层架构来满足行业应用大模型需求。在 L0 层,华为云通过 5 个基础大模型提供满足行业场景的多种技能;在 L1 层,华为云提供使用行业公开数据训练的行业通用大模型,客户也可以基于自有数据,便捷地训练自己的专有大模型;在 L2 层,华为云为客户提供更多细化场景的模型,开箱即用。
3)阿里大文娱:“提香”大模型引领妙鸭相机产品爆火
阿里大文娱是阿里拆分后的六大板块之一,集团实行董事会领导下的 CEO 负责制,并用 AIGC 将技术维度划分成 C 端和 B 端两部分 C 端是通过投资和自研,产出妙鸭相机等应用 B 端是用外部 AI 通用大模型赋能集团的影视、视频生产。
妙鸭相机是一款基于 AI 人脸识别的美图应用,用户花费 9.9 元上传 20 张多光线、多视角、多表情的上半身个人照片,就能生成一整套 AI 写真,可以选择商务写真、时尚海报、证件照、校园照、怀旧黑白风、古风随拍等多种风格。
5、AI+教育:美国侧重辅助教师,中国侧重应试
AI+教育同样是 AIGC 的重要落地方向。教育行业具备成熟的产业信息化基础、用户基础、底层数据资源,AIGC 产业链已初具雏形,其应用方向是“高频迭代”+“个性化需求”的场景。教育场景与 AI 应用方向高度契合。民生证券指 出目前 AI+教育应用及产品主要包括硬件端及软件/解决方案。硬件端(TOB/C)指终端或平台嵌入 AI 能力,学长、家长、老师可以通过平台去触达相应课程或学习相关的内容;低龄儿童的启蒙教育和口语训练;学校的数字化转型和教研系统的定制研发:包括智能课程系统、考试系统和阅卷系统;软件/解决方案(TOB)指典型的应用包括智慧校园系列,早期应用表现为普通话考评,线上口语测评和打分;随着技术持续改进,老师可基于升级系统进行课程内容规划和给出对应训练题,此外,目前也具备批改题目及给出教学方案的功能。
在市场端开发及应用方面,美国更多体现在对于考试及作业的辅助评分,减少教师时间成本及提高效率。而中国目前发展主要应用在考试准备方面,以智能筛选题目及押题为主。
1)Gradescope:作业批改模型
Gradescope 是一家美国教育科技公司,为高等教育提供在线和人工智能辅助评分工具。该公司成立于 2014 年,总部位于加利福尼亚州伯克利。
该公司的评分软件提供了用于对笔试、家庭作业以及自动评分提交的代码进行评分的工具。目前 Gradescope 使用大模型帮助老师对学生的表现评分,帮助老师节省时间,让老师们能够做更多事情教学。
到目前为止 Gradescope 已经为全球超过 200 家机构批改了超过 1200 万页的学生作业。
2)好未来 MathGPT:国内首个数学大模型
好未来的前身即学而思,2013 年 8 月 19 日正式更名为好未来。2010 年 10 月,好未来的前身学而思在美国纽交所正式挂牌交易,成为国内首家在美上市的中小学教育机构。好未来布局教育产业较为全面,构建智慧教育、教育云、内容及未来教育、K12 及综合能力和国际及终身教育五大事业群,旗下共有学而思、学而思网校、爱智康、摩比思维、励步英语、顺顺留学、家长帮等 15 个业务品牌。
8 月 24 日,好未来 CTO 田密宣布该公司自研的数学领域千亿级大模型 MathGPT 正式上线并开启公测。 MathGPT 主要面向全球数学爱好者和科研机构,是以解题和讲题算法为核心的数学垂直领域的大模型,也是国内首个专为数学打造的大模型。MathGPT 专注于数学领域,可以实现题目计算、讲解、问答等多任务持续训练和有监督微调。
使用 MathGPT 时,用文字或图片方式上传数学题,即可得到对话式的解答反馈,也可以通过“随机来一题”的按钮,随机生成数学题目并由系统给出解答。目前 MathGPT 支持中文、英文版本的 PC 端和移动端体验。MathGPT 官网显示 MathGPT 的数学计算能力已覆盖小学、初中、高中的数学题,题目类型涵盖计算题、应用题、代数题等多个类型。
MathGPT 技术报告显示,在 CEval-Math、AGIEval-Math、APE5K、CMMLU- Math、高考数学和 Math401 等 6 个公开数学评测集合的测试结果中,好未来的MathGPT 取得了多项测试的最高分数。同时 MathGPT 在 C-Eval 的初高中的全科测试集合上也均有不错的表现。
6、AI+交通:交通应用中国具备优势,智能驾驶中美处于竞争状态
大模型有协同和交互的本质,以及系统协同、信息共享、内容自动生成等特征,使其能够提升交通管理的效率和便捷性,如语音交互、知识库调用交互,各类助手、数字人、信息协同、系统联动、内容整合、报告生成、资源(指令下发)调配等,在智慧交管、智慧高速、智慧交运等领域都有所应用。
大模型可以通过算力×数据×算法的深度整合能力,结合交管日常业务,在定性和定量两个维度进行拓宽和深化。定性方面,大模型统一交管内勤 OA 业务入口,而非应用链接层面的统一;成为内勤 OA 业务办公的 AI 助手;内勤模型知识涌现可使大模型成为交管内勤业务专属“知识库”。定量方面,大模型可有机统一交通信号控制、交通状态分析等应用系统的入口,成为交管指挥调度 AI 助手,通过交通系统运行知识涌现,成为城市交通系统的“知识库”。通过将定性+定量进行结合,可打通交管内勤业务和外勤业务,秒级将交通系统数理知识和运行数据转化为内勤文档,内勤业务指令转化为交通系统运行管控指令。
自动驾驶汽车离不开感知、决策和执行这 3 个部分,自动驾驶的核心目标就是在不需要人为干预的情况下,可以安全、高效地行驶和完成各种任务,AI 大模型的出现为自动驾驶的实现提供了强大的技术支持。
AI 大模型在交通领域的应用具有以下优势,首先模型实现自动交通规则学习,其次技术上可以提高自动驾驶系统的安全性和稳定性,并且 AI 大模型能够对道路上的信息进行高效处理,提供精准的感知和决策能力,此外 AI 大模型具有较强的可迭代性和适应性,最后 AI 大模型可以从多个自动驾驶车辆中收集数据,并通过联合学习的方式进行模型的优化。
目前在交通的大模型应用上,我国具备了较大优势,较美国处于领先地位。我国政府在环境授权和放松管制方面所做的努力,在国内培育了一个友好的环境。随着中国政府不断放宽道路规范,数据收集就变得相对容易,进而让国内科技公司受益。
在自动驾驶方面我国与美国正处于竞争状态,从开始美国的领先到现在我国已具备竞争市场份额的实力。我国计划约在 2040 年完全淘汰内燃机,这使得我国成为最大的电动汽车市场,未来有可能会成为全球最大的自动驾驶市场,在政策的支持力度以及市场需求方面,我国未来很大可能居于全球首位。这有利于对国内科技公司催化,产出更优的技术应对庞大的市场需求。
1)百度:基于交通大模型的全域信控缓堵解决方案
在交通行业领域,百度首个定义大模型与交通结合的应用场景。
3 月,百度基于文心大模型在高速公路领域发布了数字人简璐璐;4 月 18 日,在长沙 2023 中国道路交通安全创新与合作大会上,百度发布“基于交通大模型的全域信控缓堵解决方案”,打响了交通大模型应用的第一枪。
百度发布的基于交通大模型的全域信控缓堵解决方案是百度在芯片、框架、大模型、应用场景等全栈布局下的一个典型现象级应用。
该方案底层包括实时感知、机器视觉、交通预测、问题诊断、策略推荐、配时优化、个性化提示等交通大模型,能够提供全域感知、全域优化、全域协同和全域服务四大能力,实现信控优化的代际提升,可实现超千规模路口的全域拥堵治理。
依托文心大模型的能力,百度通过在智能交通领域打造交通大模型,构建交通感知、决策、认知、预测的完整能力,重构已有解决方案和产品,可全面升级 G 端(交通管理)/B 端(交通运输)/C 端(出行服务)的交通场景应用和用户体验。
最新发布的 18.5.0 版本的百度地图,结合文心交通大模型 beta 版能力,全面提升车位级导航、车道级导航、隧道导航、红绿灯倒计时、实时公交地铁等产品体验。据了解,文心交通大模型 Beta 版是面向实时交通场景的大模型,可实现对实时交通数据的刻画、感知、预测和调度,从而为用户提供更加精准、高效、安全的导航服务。
在高速公路领域,百度联合河北高速集团发布了基于交通大模型的数字人简璐璐。作为高速行业专家、业务助手、出行伴侣和形象大使,“简璐璐”服务于路网监测、应急指挥、养护管理、公众出行全环节,可以结合用户问题,提供全新对话式交互,实时给出精准答复,让设施更简约、流程更简化、沟通更简单、服务更简洁。
传统的高速业务系统主要是页面型展示,指标和报表都相对固化,展示内容单一,难以支持全局评估。在这种情况下,百度打造基于数字人的全新交互体验,以全新的自然语言完成交互,通过数字人的联动系统和数字化的监控大屏,实现全新的业务交互。
数字人在 NLP(自然语言处理)和 NLU(自然语言理解)的基础上定义了路网运行监测,应急救援管理,包括协同服务管理、仿真决策和大屏等 62 项指令集。通过指令集实现极简交互、高效的协同,实现跨系统、跨功能、跨 API、跨数据的打通,有效提升业务效率
2)毫末智行 DriveGPT: 首个将 GPT 技术用于自动驾驶领域的公司
在自动驾驶领域,目前明确提出相关模型的是毫木智行的 DriveGPT。
毫末智行是长城汽车投资的自动驾驶公司。毫末智行的前身是长城汽车的智能驾驶前瞻部,于 2019 年从长城汽车独立。长城汽车技术副总工程师、长城汽车智能驾驶系统开发部部长张凯担任董事长,前百度智能汽车事业部总经理顾维灏 2021 年加入,并担任 CEO。
2023 年 1 月,毫末在对 Transformer 大模型前沿探索的基础上,率先同时推出了视觉自监督大模型、3D 重建大模型、多模态互监督大模型、动态环境大模型、人驾无监督认知大模型等五个自动驾驶大模型,成为行业首个将 GPT 大模型技术引用到自动驾驶认知决策当中的自动驾驶公司。
DriveGPT 的底层模型与 ChatGPT 一样,都采用了生成式预训练模型架构,使用了大规模无监督的数据进行初始模型的生成,也都采用了 Prompt 微调方式和 RLHF 人类反馈强化学习的方式进行模型效果的优化;二者的不同之处在于ChatGPT 输入输出的是自然语言的文本,而 DriveGPT 输入输出的分别是融合感知场景序列和生成的预测场景序列,双方应用的场景不同,ChatGPT 主要用于自然语言处理领域,而 DriveGPT 主要用于驾驶场景决策领域。
在自动驾驶认知决策中,DriveGPT 通过引入驾驶数据,使用 RLHF(人类反馈强化学习)技术,对自动驾驶认知决策模型进行持续优化,同时毫末正在将感知能力融入到 DriveGPT 大模型训练当中,形成一整套的端到端自动驾驶能力模型。DriveGPT 也将具备道路驾驶场景的理解和识别、道路驾驶场景的重建与生成,以及智能驾驶辅助、驾驶能力测评等能力。
不过,毫末智行技术副总裁艾锐也表示,目前 DriveGPT 的应用,对于汽车算力的需求还是太大,还需要一定的时间才能解决。同时在算力提升后,对汽车的能耗也会带来不小的挑战,未来需要找到一种低成本的兑现方式。从目前来看,这种能力只能部署在云端,让大家通过联网去使用。
3)商汤日日新 SenseNova
4 月 10 日,商汤科技 SenseTime 举办技术交流日活动,发布了“日日新 SenseNova”大模型体系,该体系可提供自然语言、内容生成、自动化数据标注、自定义模型训练等多种大模型及能力,同时结合决策智能大模型,为 AGI 实现提供重要起点。
5 月,商汤在赛文年会上首次全面介绍了对交通+大模型应用场景的理解,基于商汤日日新 SenseNova 大模型体系对交通产品体系进行探索和落地应用,认为“入口”、“AI 助手”、“知识库”是大模型在交通管理领域应用的三大表现形式。
4)拓维信息+华为盘古大模型
在 7 月 8 日上午举行的盘古大模型合作伙伴签约仪式上,拓维信息(002261)与华为正式签署合作协议,成为盘古大模型生态合作伙伴,基于盘古大模型开发交通行业大模型,共建大模型生态。
据了解,拓维信息是华为云首批同舟共济合作伙伴,也是华为“大模型+鲲鹏+昇腾 AI+开源鸿蒙”全方位战略合作伙伴,该公司深耕行业数字化二十余年,在交通、教育领域积累了海量数据(603138)和较深的认知,而盘古大模型在交通行业的落地,离不开行业数据的支撑和对行业的深刻理解。
拓维信息相关负责人介绍,接下来,其将进一步深化与盘古大模型在数据、算法以及服务等方面的交流与合作,加速推动交通行业大模型落地。
7 月 26 日电,拓维信息在互动平台表示,公司交通行业大模型目前还处于验证和研发阶段,公司将加速推进正式的应用。公司将基于盘古大模型开发交通行业大模型,主要解决交通领域智能场景的快速实现和准确率提升,包括但不限于道路治理、自由流收费、事件应急预警等。
5)“通义千问”+千方科技“梧桐”行业大模型
在商汤科技发布“日日新 SenseNoya”大模型的第二天,2023 年阿里云峰会在北京召开,峰会上发布了 AI 大模型“通义千问”。阿里巴巴集团董事会主席兼 CEO、阿里云智能集团 CEO 张勇在会上表示,阿里巴巴所有产品未来将接入“通义千问”大模型,进行全面升级改造。
阿里云智能交通物流行业总经理张磊在赛文年会上表示:“阿里云具备研发生成大模型的关键要素,愿携手客户与伙伴共同探索大模型在交通物流行业的智能化应用。”
4 月 26 日,2023 阿里云合作伙伴大会上,千方科技作为“千问伙伴计划”首批唯一交通领域合作伙伴受邀参会,表示将与阿里云携手推动大模型在交通行业落地应用,探索智慧交通更优解。作为首批唯一交通领域合作伙伴,与阿里云携手推动大模型在交通行业落地应用,助力丰富应用场景,为交通基础设施的数国冰合车字化、网联化与智能化建设注入新动能。
次月,千方科技旗下宇视科技发布宇视行业大模型“梧桐“并展示产品端第一阶段的落地成果。这是继加入“千问伙伴计划”,宣布携手阿里云共创交通大模型后,千方科技拥抱 AIGC 技术的又一重要落地。
6)北京交通大学研发国内首个开源综合交通大模型 TransGPT·致远
7 月 27 日,北京交通大学联合中国计算机学会智慧交通分会与足智多模公司等正式开源了,自主研发的国内首个综合交通大模型:TransGPT·致远。(开源地址:https://github.com/DUOMO/TransGPT)。
TransGPT 不仅可以用于学术研究,通过邮件申请并获得官方许可后,可以免费商业化。(申请邮箱地址 duomo_tech@163.com)。
据悉, TransGPT 主要致力于在真实交通行业中提供各种功能,包括交通情况预测、智能咨询助手、公共交通服务、交通规划设计、交通安全教育、协助管理、交通事故报告和分析、自动驾驶辅助系统等,例如,通过实时监测和分析车辆、道路、信号灯等信息。
TransGPT 还可以为道路工程、桥梁工程、隧道工程、公路运输、水路运输、城市公共交通运输、交通运输经济、交通运输安全等行业,提供类ChatGPT 的小百军问答服务,例如,肇事逃逸将面临哪些处罚?
训练数据方面,TransGPT 致远的训练基于约 34.6 万条交通领域文本数据(用于领域内预训练)和 5.8 万条交通领域对话数据。数据内容包括:科技文献、统计数据、工程建设信息、管理决策信息和科学数据等。
1)交通安全教育:交通大模型可以用于生成交通安全教育材料,如安全驾驶的建议、交通规则的解释等。
2)智能出行助手:在车辆中的智能助手可以使用大型交通大模型来理解和生成更自然、更复杂的对话,帮助驾驶者获取路线信息、交通更新、天气预报等。
自动回答关于公共交通服务的问题,如车次、票价、路线等。这可以提高服务效率并提升乘客体验。
3)交通管理:通过实时监测和分析车辆、道路、信号灯等信息,协助智能协调交通流量,减少交通拥堵。分析社交媒体或新闻报道中的文本信息,预测交通流量、交通堵塞或事故的可能性。
同时,该模型能分析交通事故历史和特征,给出相应对策和方案,减少交通事故的发生。
4)交通规划:交通大模型可以帮助分析公众对于交通规划提案的反馈和意见,提供决策者更全面的信息。
5)交通事故报告和分析:交通大模型可以帮助快速理解和分类交通事故报告,提供事故原因的初步分析。
交通政策研究:大型交通大模型可以用于分析公众对于交通政策的反馈,或者生成关于交通政策影响的报告。这可以帮助政策制定者更好地了解政策的实际效果。
研发团队在交通 benchmark 上进行了 zero-shot 评测,并获得了不错的成绩。
交通安全教育方面:生成交通安全教育材料,如安全驾驶的建议、交通规则的解释等;
交通情况预测方面分析社交媒体或新闻报道中的文本信息,预测交通流量、交通堵塞或事故的可能性;
事故报告和分析方面:理解交通事故报告,提供事故原因的初步分析;
交通规划方面:分析公众对于交通规划提案的反馈和意见,提供决策者更全面的信息。
多模态
TransGPT 已经具备面向 BIM 模型审核员、智能运维、智能咨询等场景的应用落地能力,将大幅度促进铁路工程等数字化转型和智能化提升。
研发团队表示,交通大模型采用了基于 Transformer 架构的文本大模型、多模态大模型与实时场景数据调用能力,整体上形成综合交通大模型为基础设施、辅以交通细分行业应用的架构。
支持实时类应用,包括:驾车规划、公共交通规划、(逆)地理编码查询等落地场景应用能力,能够促进铁路交通等领域的数字化转型和智能化提升。
7 月 14 日,佳都科技集团、云从科技集团、重庆交通开投集团联合发布知行城市交通行业大模型,并签署战略合作协议,三方将就深入开展城市交通技术研发及应用落地达成战略合作。
知行交通行业大模型将深耕交通行业,大模型可以实现对轨道车站客流、轨道站点与公交衔接、道路的拥堵治理等等问题进行人工智能深加工和科学管理,并加速大模型在产业价值的大规模应用。
此外,在智能大交通方面,大模型垂直应用场景有四个阶段:把人类掌握的知识注入行业大模型里面;利用大模型能力成为人机协同生产力助手;结合行业知识与专家经验形成交通大模型,提质增效;将交通系统生产与管理变成若干个自动或由人监督的自动化运行系统。
重庆交通开投科技公司总经理袁轶介绍,重庆交通开投集团扎实推进数字重庆建设,促进人工智能与实体经济深度融合,携手佳都科技集团、云从科技集团,通过以“知行交通大模型”为代表的 AI 人工智能与重庆交通运行数据进行结合,赋能重庆轨交、公交、高铁、交通枢纽的数字大交通建设和运营,实现乘客服务、高效运营、应急联动、智能运维等创新应用落地,为重庆交通行业提供智能化的解决方案和决策支持。
此次佳都科技、云从科技、重庆交通开投集团合作,将为重庆智能轨道交通技术创新提供统一的数字化底座。各方将继续开展基于智能交通大数据应用开发、智慧化运营、运维等方面的探索并产业化,加速在重庆轨道交通合作项目中落地推广应用,真正实现数字化改革赋能轨道交通出行服务迭代升级。
8)旷视科技智驾产品
从 2021 年初大力研发智驾方案到宣布推出量产方案,旷视用时不到三年。
2023年6月中旬,在加拿大举力的 AI 顶会 CVPR2023 上,旷视科技获得自动驾驶国际挑战 OpenLane 拓扑关系赛道第名。CVPR2023 自动驾驶国际挑战赛分为四个赛道,包括、OnlineHDMapConstruction(在线高精地图构建)赛道等。
“OpenLane 拓扑关系挑战赛,本质上是一个通过实时感知来生成地图的比赛。目前大家对道路拓扑结构(如车道线、车速标识等)的感知,主要是靠高精地图来提供,而要去高精地图的话,那就只能把这些东西感知之后,再构建自己的道路拓扑结构。”旷视科技智驾业务总裁刘伟对雷峰网解释说,“这个比赛的现实意义在于,可以让旷视在‘去高精地图’这条路上越走越扎实,最终在城区也能实现‘去高精地图’。 ”凭借在这一赛事上的出色表现,一向“神秘”的旷视自动驾驶业务逐渐浮出水面。
简单来说,旷视的产品分为三个配置:标准版、专业版、旗舰版,分别对应 10-15 万元车型、15-30 万元车型和 30 万元车型。其中标准版方案具备高速 NOP 功能,专业版方案具有城市 NOP 功能,最高配置的旗舰版方案则具备增强的城市 NOP 功能以及更强的安全冗余。
当下旷视智驾业务的发力点则主要在标准版和专业版方案。“我们瞄准的是量产市场,旷视希望做到在中低价位车型中达到一年几百万辆的销量,这两个版本的方案都是不带激光雷达的,成本相对较低,可以服务于 10 万 -30 万元的车型。”刘伟表示。
8、总结
目前,中美在 AI 大模型方向领先世界各国,然而二者的竞争也已经明牌,中美两国在 AI 大模型各方面的表现各有胜负,其中以谷歌为代表的科技巨头长期投身于基础理论的研究,使得美国引领者人工智能的发展潮流,依托浓厚的工程师文化,美国在基础大模型上保持领先优势。在一级市场上,美国对大模型的投资也比较积极,其中以英伟达、微软、Salesforce 等为代表的科技巨头成为美国 AI 领域最重要的“独角兽猎手”,在一级市场的大手笔投入,为美国人工智能的发展积蓄了力量。
此外,美国各个行业整体的信息化水平较高,积累了丰富的结构化数据,这为美国做大模型落地打下了基础。
因此,本报告认为,美国在 AI 大模型发展的基础理论与基础数据方面,有着独特的优势,这也为 AI 大模型的使用打下了基础,尤其是在医疗研发等方向其会继续保持着先发优势。
相比美国,国内一直扮演着追随者的角色,在基础模型方面,中美之间的差距并不大,“重应用轻基础”的研发理念,以及国内庞大的下游需求,让国内机构更加专注于落地应用的研究,可以说,在 AI 大模型的应用上,国内是更胜一筹的。
一方面是,国内一级市场更多是关于大模型应用的创业项目,另一方面,各行业较成熟的企业,例如教育行业的好未来,办公软件行业的金山办公,医疗行业的医云科技等等,均依托在各自行业的深耕,或外接基础模型,或利用开源模型自研模型来使所从事的行业用上 AI 大模型。
不过,也应该注意到,国内不少行业尚未完成信息化,基础数据的匮乏使得 AI 大模型在某些行业寸步难行,此外,算力制约成为中美 AI 竞争的一把利刃,努力冲破算力制约是 AI 发展路上的头等大事。
中美 AI 竞争的过程中,优劣明显,但相比美国在应用上所处的下风,我国在算力及数据等 AI 发展基础要素上的短板更值得注意。
来源:钛媒体


